Cerebras Announces its Inference product for the fastest inference for Generative AI

Hey Everyone,
Cerebras is an American artificial intelligence (AI) company that specializes in building computer systems for complex AI deep learning applications. Cerebras Systems launched on Tuesday a tool for AI developers that allows them to access the startup's outsized chips to run applications, offering what it says is a much cheaper option than industry-standard Nvidia processors.
So why is this a big deal? Like Groq, it speeds up responses from frontier models and future agentic AI systems. It's also using their third-generation Wafer Scale Engine (WSE-3). Try to tool here.
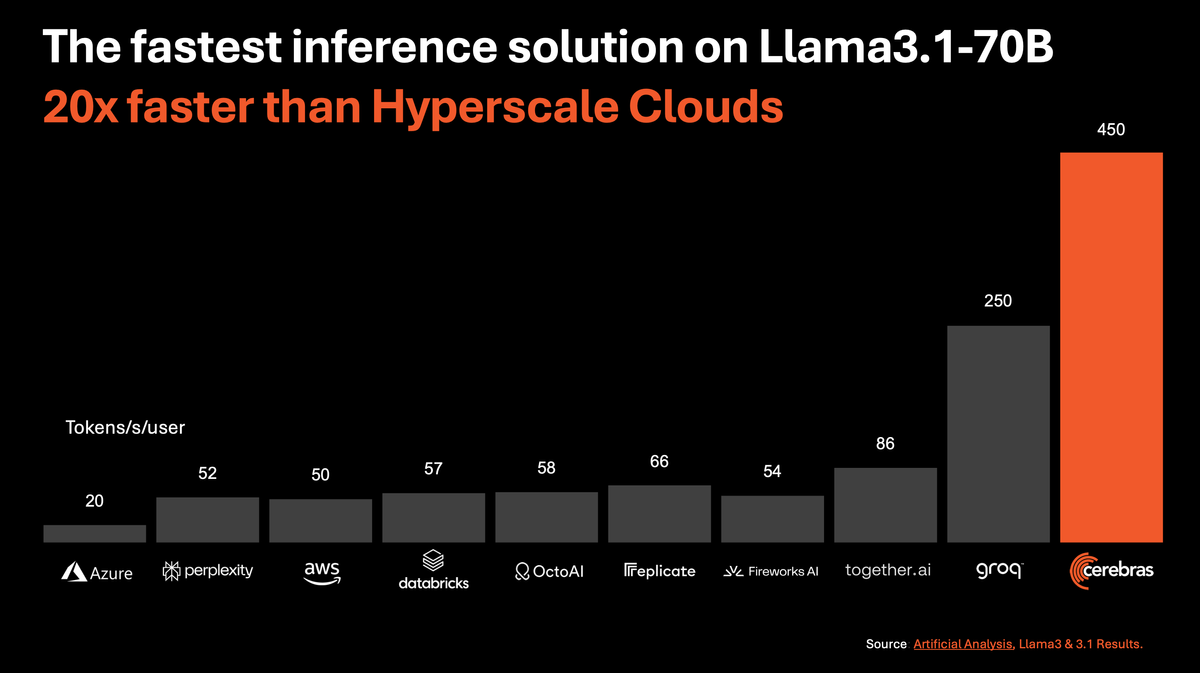
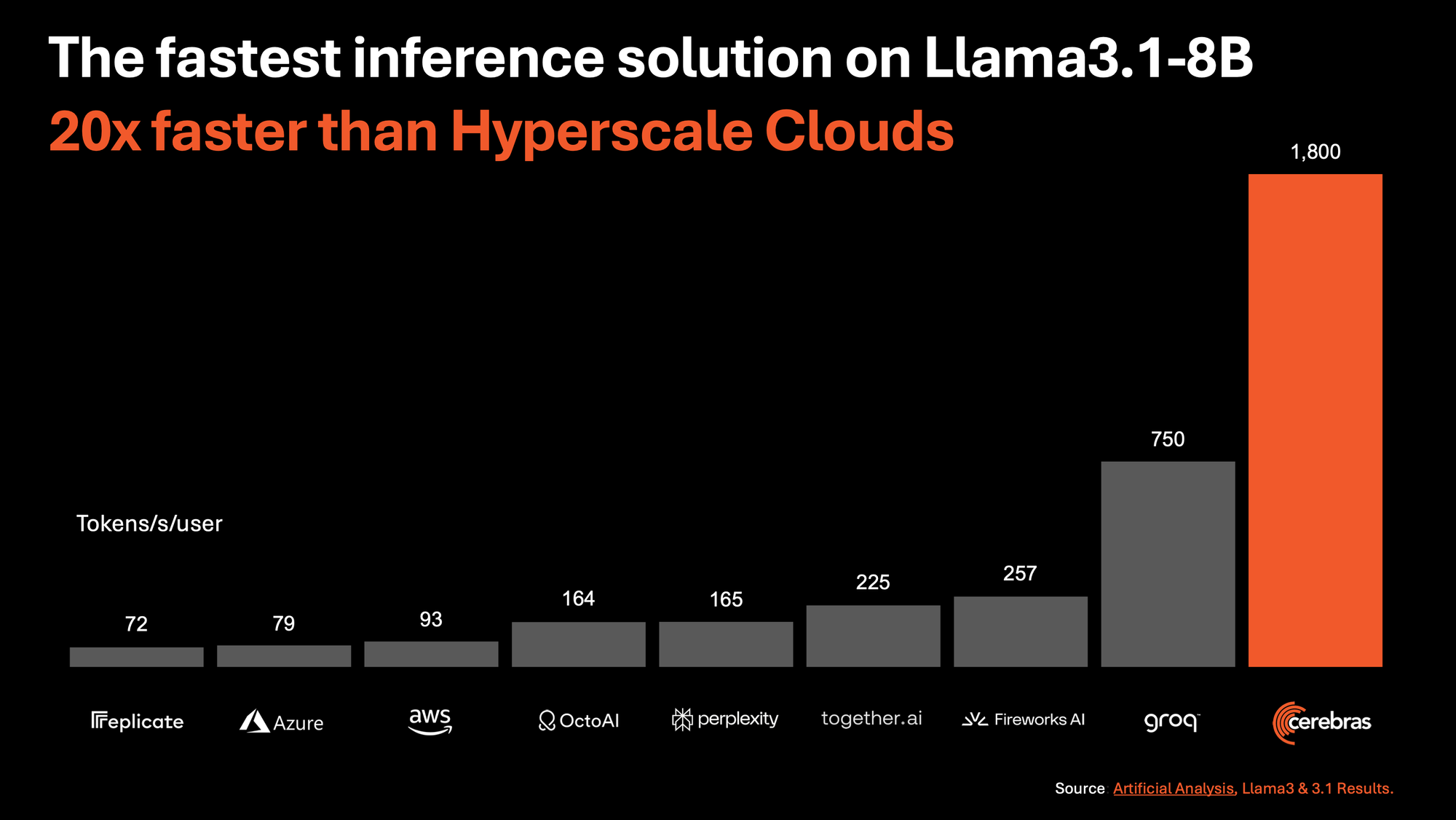
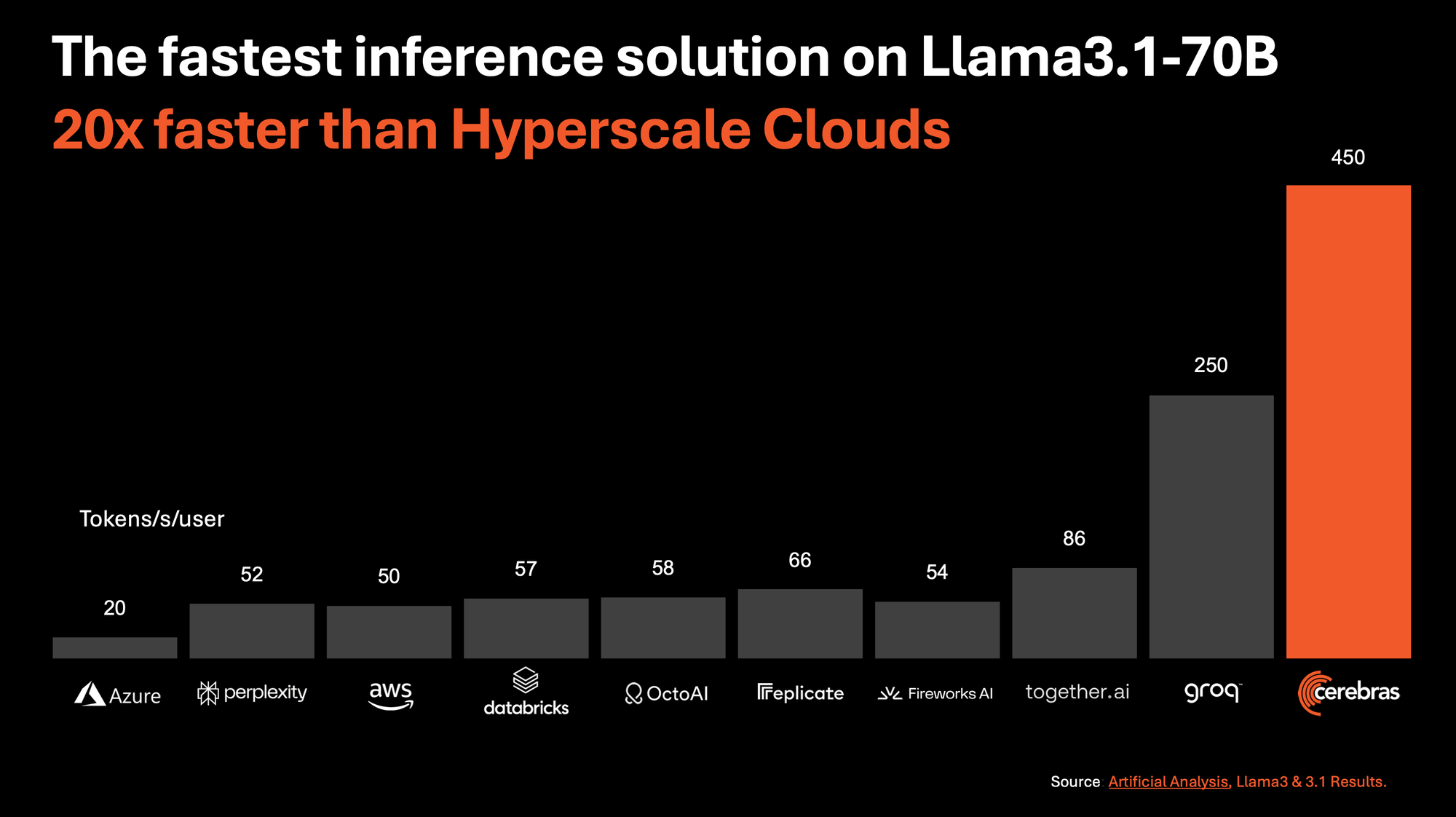
🏎️ Speed: 1,800 tokens/sec for Llama 3.1-8B and 450 tokens/sec for Llama 3.1-70B, 20x faster than NVIDIA GPU-based hyperscale clouds.
💸 Price: Cerebras Inference offers the industry’s best price-performance at 10c per million tokens for Llama 3.1-8B and 60c per million tokens for Llama-3.1 70B.
🎯 Accuracy: Cerebras Inference uses native 16-bit weights for all models, ensuring the highest accuracy responses.
🔓 Access: Cerebras Inference is open to everyone today via chat and API access.
Cerebras launches AI inference tool to challenge Nvidia
Cerebras Inference according to the company, is priced at a fraction of GPU-based competitors, with pay-as-you-go pricing of 10 cents per million tokens for Llama 3.1 8B and 60 cents per million tokens for Llama 3.1 70B.
The company plans to offer several types of the inference product via a developer key and its cloud. The company will also sell its AI systems to customers who prefer to operate their own data centres.

They have offices in Sunnyvale, San Diego, Toronto, Tokyo and Bangalore and are a fascinating startup.
This could dramatically lower the cost of AI interference. Cerebras Inference is 20 times faster than NVIDIA GPU-based solutions in hyperscale clouds. Starting at just 10c per million tokens, Cerebras Inference is priced at a fraction of GPU solutions, providing 100x higher price-performance for AI workloads.
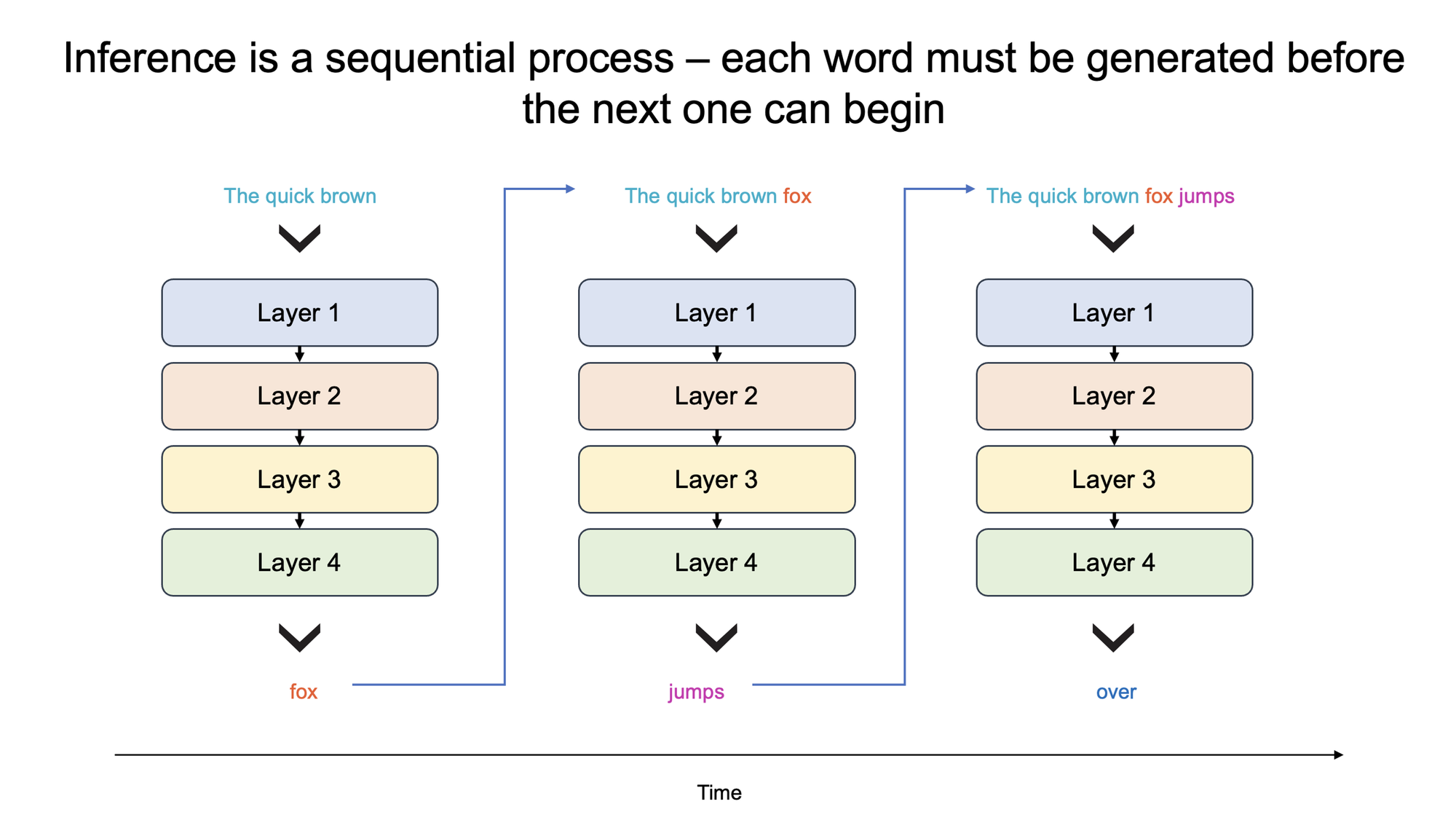
Today GPU inference can still feel slow:
Unlike alternative approaches that compromise accuracy for performance, Cerebras offers the fastest performance while maintaining state-of-the-art accuracy by staying in the 16-bit domain for the entire inference run.
This is important because also AI inference is the fastest growing segment of AI compute and constitutes approximately 40% of the total AI hardware market. Cerebras Systems is a team of pioneering computer architects, computer scientists, deep learning researchers, and engineers of all types.
It's WSE-3 enables different outcomes:

Cerebras Inference is powered by the Cerebras CS-3 system and its industry-leading AI processor – the Wafer Scale Engine 3 (WSE-3). Unlike graphic processing units that force customers to make trade-offs between speed and capacity, the CS-3 delivers best in class per-user performance while delivering high throughput.
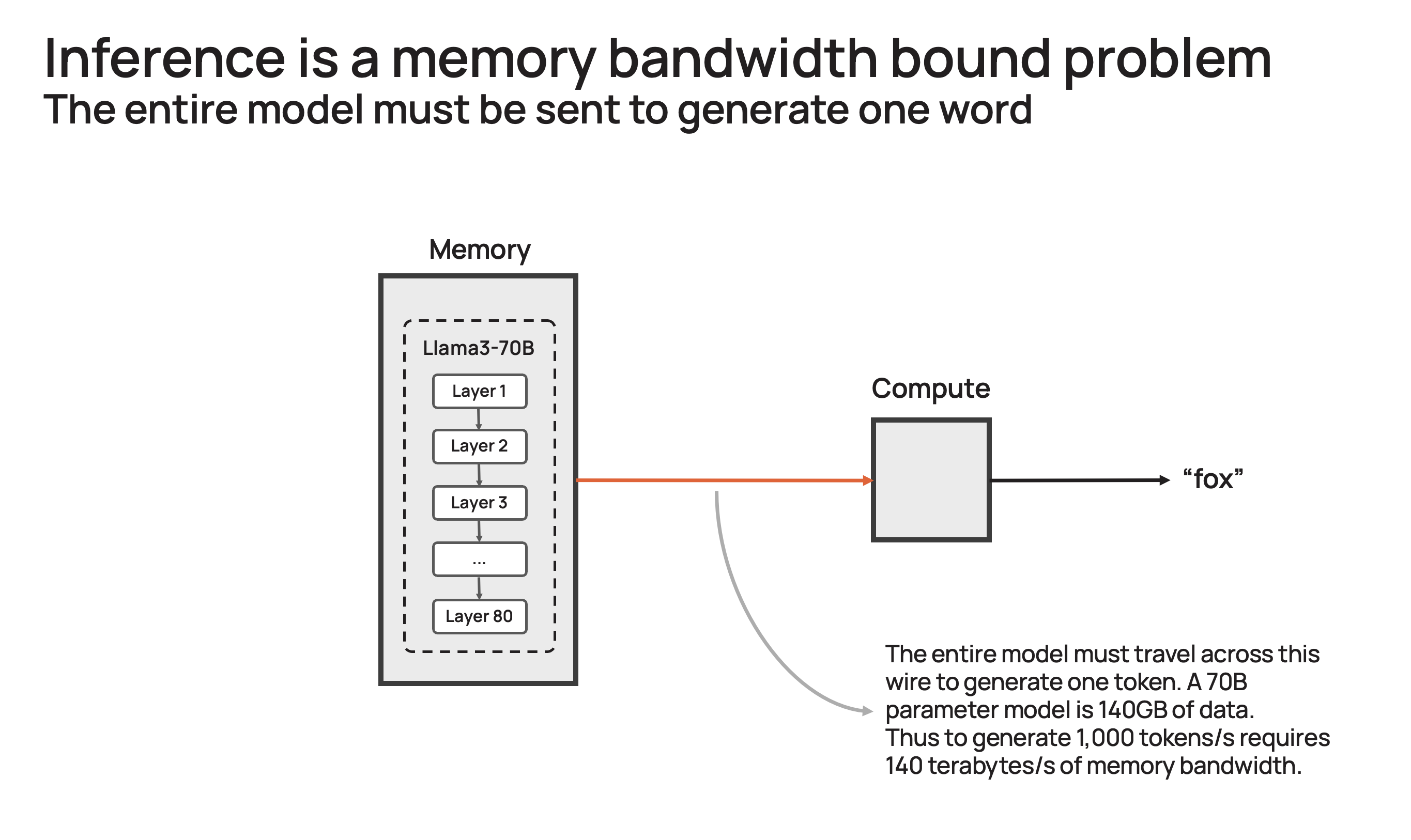
How Cerebras lifts the memory bandwidth barrier
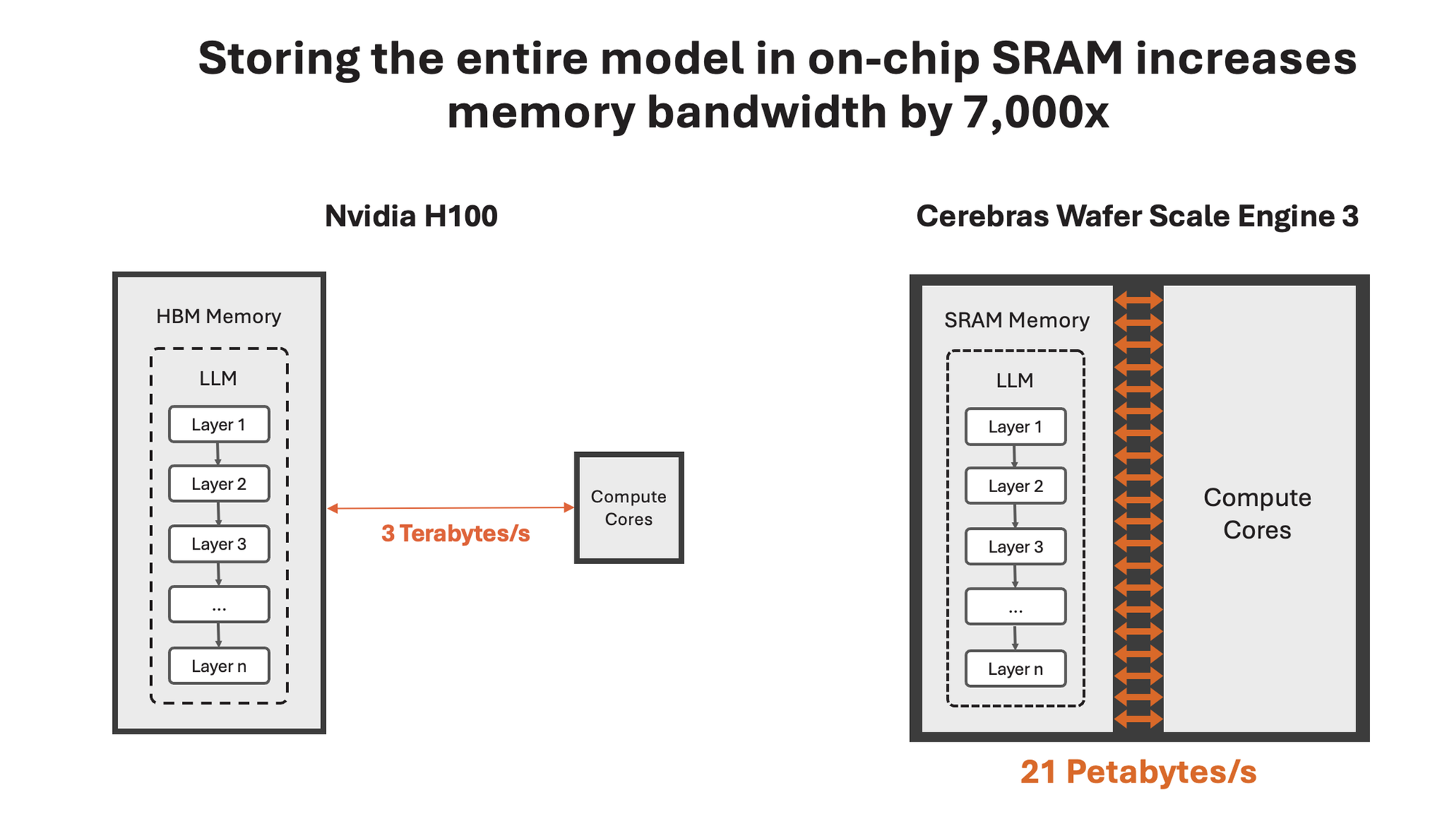
Cerebras solves the memory bandwidth bottleneck by building the largest chip in the world and storing the entire model on-chip. With their unique wafer-scale design, we are able to integrate 44GB of SRAM on a single chip – eliminating the need for external memory and for the slow lanes linking external memory to compute.
In total, the WSE-3 has 21 petabytes/s of aggregate memory bandwidth – 7,000x that of an H100. It is the only AI chip with both petabyte-scale compute and petabyte-scale memory bandwidth, making it a near ideal design for high-speed inference.
Might this be one of the systems for the future? Cerebras inference is designed to serve models from billions to trillions of parameters. They are also going IPO. Cerebras is aiming to go public and filed a confidential prospectus with the Securities and Exchange Commission this month.
This tool is designed to deliver significantly higher performance compared to existing solutions, particularly those based on NVIDIA GPUs. Cerebras Inference can deliver 1,800 tokens per second for the Llama 3.1 8B model and 450 tokens per second for the Llama 3.1 70B model.
So this is a fairly exciting development in late August, 2024. Access to Nvidia graphics processing units (GPUs) - often via a cloud computing provider - to train and deploy large artificial intelligence models used for applications such as OpenAI's ChatGPT can be difficult to obtain and expensive to run, a process developers refer to as inference. As more competitors come to the market with new solutions, it's going to lower the price of compute and inference in various ways, even as Generative AI models become even more powerful, large and capable.



